Developer adventure: a quest to find a large dataset of beers
Last week I had a small idea for a web application where one has an overview of "all" different beers in the world and gives you the option to tick off the ones you have tried.
So I had a quick Google for 'beer+api' and came to this list of APIs by RapidAPI. I noticed they have Untappd on there, and quickly remembered they do exactly what I conjured up (plus more, obviously) 😅
Spoiler alert / Warning
This post is not a clear-cut walkthrough on how to scrape the data we need. Instead, it's me taking you along the proces of finding the dataset. The considerations, attempts and the plan B's while trying to achieve the goal. Don't expect unicorns 🦄 and rainbows 🌈!
Finding the data
Nonetheless I was curious as to how much data they have and if it was possible to see into this dataset somehow. I opened up their website and pulled up the Inspector in Chrome. Searching for "Leffe Blond" gave me 50 more results than I expected so I assume their data set is quite HUGE. However, by monitoring the Network Requests I couldn't find anything useful which means they render the results on the backend. That's a shame challenge.
However, I noticed the Search box in the top right and when I started typing I realized there were realtime results, being fetched by API calls going out to an Algolia service. Good stuff.
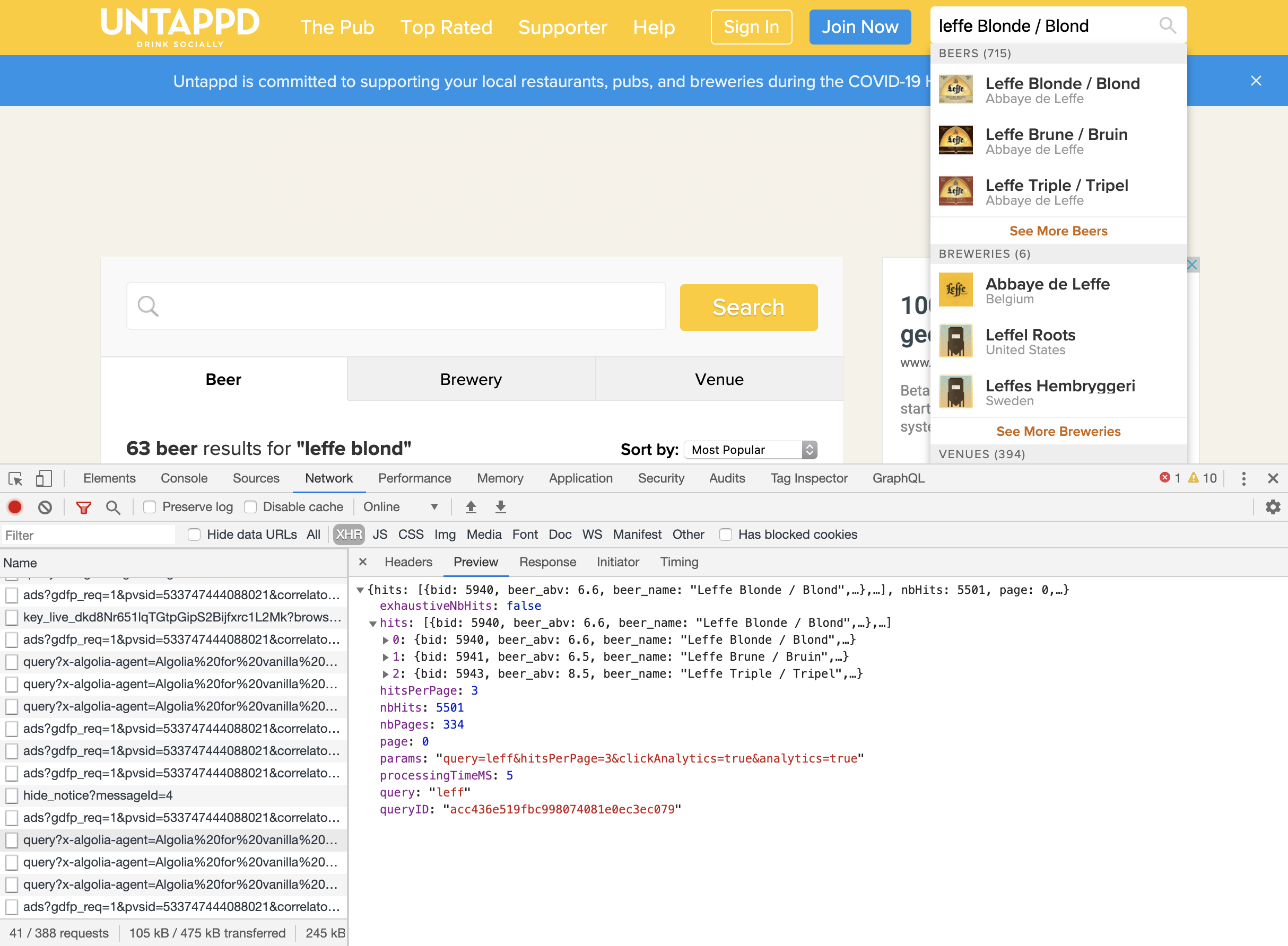 Untappd's Algolia Search
Untappd's Algolia Search
Analyzing the data stream
So, looking at the Network Inspection tab again we can see a call is done to an URL like this:
https://9wbo4rq3ho-dsn.algolia.net/1/indexes/beer/query?x-algolia-agent=Algolia%20for%20vanilla%20JavaScript%203.24.8&x-algolia-application-id=XXX&x-algolia-api-key=XXX
(I XXX-ed out the application id and key. They are public, but still, didn't feel like posting them here 👌)
The response of this call is quite verbose in its data, which is of course perfect. Among meta data like amount of results, page counts and detected params the info we see the data we are really after is inside hits:
"hits": [
{
"bid": 5940,
"beer_abv": 6.6,
"beer_name": "Leffe Blonde / Blond",
"beer_index": "abbaye de leffe leffe blonde blond",
"brewery_label": "https://untappd.akamaized.net/site/brewery_logos/brewery-5_60e12.jpeg",
"brewery_name": "Abbaye de Leffe",
"brewery_id": 5,
"type_name": "Belgian Blonde",
"type_id": 242,
"homebrew": 0,
"in_production": 1,
"popularity": 639328,
"alias_alt": [
"leffe blonde superieure",
"abby of leffe blondeblond abby ale",
"big leffe blond",
"blond grande 15l",
"leffe blond vanille kruidnagel",
"leffe blonde belgium pale ale"
],
"spelling_alt": [],
"brewery_alias": [],
"beer_label": "https://untappd.akamaized.net/site/beer_logos/beer-5940_9118b_sm.jpeg",
"beer_index_short": "abbayedeleffeleffeblondeblond",
"beer_name_sort": "Leffe Blonde / Blond",
"brewery_name_sort": "Abbaye de Leffe",
"rating_score": 3.58383,
"rating_count": 354960,
"brewery_beer_name": "Abbaye de Leffe Leffe Blonde / Blond",
"index_date": "2020-04-21 10:12:50",
"objectID": "5940",
"_highlightResult": {
// Omitted for brevity
}
},
etc. !
We can see we pretty much get all the information we need. I usually go over all the properties within a dataset to see if I can figure out what it is and decide if I find them interesting enough to eventually port to a new dataset I can work with myself. Let's see if we can find any interesting ones:
I assume bid is their internal Beer ID, which we can probably use to consolidate the results and check if we have already scraped the record.
I didn't think about this yet, but I know 6.6% is the alcohol percentage of Leffe, so beer_abv looks to be the Alcohol by Volume. Can't hurt to have this info!
beer_name is obvious, and something we definetely want in our own dataset.
The brewery_label has a reference to an image, which must be the brewery image and brewery_name the name itself.
brewery_id is obviously a reference to the brewery data, which I saw is being loaded with a similar call, so good to keep this in.
Looking at the value of type_name we can see that type_id could have been very interesting but since I don't see how we could retrieve a list of all the types it's pretty much useless.
Going down a bit we can see that we definately want the value of beer_label as it's an image of the beer.
Below we see more variations and alternatives for both the beer and brewery name, which is not relevant for us at the moment, and _highlightResult is probably meta data from Algolia.
So that's pretty cool, we have found out we can fetch the following useful data:
- Beer ID, Name, Image and ABV
- Brewery ID, Name and Image
If we look again at the network tab at the other requests we also see a similar request for the breweries and one for the venues. The breweries is interesting, the venues I don't care about at the moment.
Let's see what we get from the breweries response data:
{
"brewery_id": 5,
"brewery_name": "Abbaye de Leffe",
"brewery_index": "abbaye de leffe",
"brewery_alias": [],
"brewery_beer_count": 32,
"brewery_image": "https://untappd.akamaized.net/site/brewery_logos/brewery-5_60e12.jpeg",
"brewery_page_url": "/w/abbaye-de-leffe/5",
"brewery_country": "Belgium",
"brewery_popularity": 1122864,
"brewery_city": "Leuven",
"brewery_state": "Vlaanderen",
"brewery_type_id": 1,
"brewery_name_sort": "Abbaye de Leffe",
"brewery_homebrewery": 0,
"brewery_name_exact": "abbaye de leffe",
"_geoloc": {
"lat": 50.89,
"lng": 4.7072
},
"objectID": "5",
"_highlightResult": {
// Omitted for brevity
}
}
We can see there is a few fun facts we might want to be interested in besides the essentials we already had (id, name, image). We can see there is a beer_count which is cool we can see the country, city, state and even a geo location.
Awesome.
Scraping the API calls
Looking at the request we see it's a POST to an Algolia service. That's a shame as GET requests are a lot easier to work and test with, but looking at the data that needs to be posted I think we shouldn't have any problems.
Now, I don't recommend doing this, because we are essentially going to 'steal' the data by writing an application that scrapes the API calls, but hey, it's there and it's for learning purposes only, right? 🤐
So our goal is to create an automated way of executing these Algolia search requests and then storing all the data locally. I usually go with a JSON dataset first, to save the hassle of setting up databases and models. We can always fancy it up later.
Setting the Node stage
My preferred weapon of choice for anything like this is NodeJS. It's easy to get started and iterate with.
Let's create a file scrape_beers.js in some folder. We probably first want to see if we can retrieve the data, so let's pull in a library called Axios.
$ yarn add axios
Next, let's fill up our scrape_beers.js file. Right clicking on the network request gives us the option 'Copy as Node.js fetch', which gives us:
fetch(
"https://9wbo4rq3ho-dsn.algolia.net/1/indexes/beer/query?x-algolia-agent=Algolia%20for%20vanilla%20JavaScript%203.24.8&x-algolia-application-id=XXX&x-algolia-api-key=XXX",
{
headers: {
accept: "application/json",
"accept-language": "en-US,en;q=0.9,nl;q=0.8",
"content-type": "application/x-www-form-urlencoded",
"sec-fetch-dest": "empty",
"sec-fetch-mode": "cors",
"sec-fetch-site": "cross-site",
},
referrer: "https://untappd.com/search?q=leffe+blond",
referrerPolicy: "no-referrer-when-downgrade",
body:
'{"params":"query=leff&hitsPerPage=3&clickAnalytics=true&analytics=true"}',
method: "POST",
mode: "cors",
}
);
So, we know the URL we have to POST to, and looking at the body we know we need to send a JSON object of params with a query, hitsPerPage and something about analytics. Let's translate that to an axios request in our scrape_beers.
const axios = require("axios");
axios({
method: "POST",
url:
"https://9wbo4rq3ho-dsn.algolia.net/1/indexes/beer/query?x-algolia-application-id=xxx&x-algolia-api-key=xxx",
data: '{"params":"query=leffe&hitsPerPage=3"}',
})
.then((res) => {
console.log(res.data.hits);
})
.catch((err) => {
console.log(err.response.data);
});
I didn't arrive to this straight away. At first I tried to pass the data as a JSON object, but this gave me a 400 error. When adding a .catch to the axios request it said:
message: 'Object must contain only one string attribute: params near line:1 column:11',
So I figured I would just pass it as a string in the data property and then it was fine. We're getting results back 😄
This is a good way to debug btw. I often see developers trying out API calls without a catch-block, which makes the process of finding the right parameters a lot longer and intensive.
In addition, I tried removing all parameters that are not required (in this case clickAnalytics and analytics). It doesn't hurt to leave them in, but I like to keep these things as small as possible.
Anyway, now that we have a script that can retrieve the results, let's see what we can do to get ALL the beers 🤔
Extending the scrape script
Looking back at the meta data we get back in the JSON response, we can see this part
nbHits: 711,
page: 0,
nbPages: 237,
hitsPerPage: 3,
This information is pretty much exactly what we need to retrieve all the results for our search query "leffe". Apparently there's 237 pages of results with 3 results per page. We already saw we can pass the hitsPerPage, let's quickly check if we can also pass the page by adding it to the data string
data: '{"params":"query=leffe&hitsPerPage=3&page=10"}'
And sure enough, we now get page 10. Brilliant. So we can use page and npPages to write a loop to get all the JSON responses. However! This gives us only a list of the "leffe" beers. And we want them all. We should think about what we can search for which gives us ALL the possible results. How about searching for an empty string ("") ..
data: '{"params":"query=&hitsPerPage=3"}'
This gives us results (yay!):
nbHits: 2860354,
page: 0,
nbPages: 334,
hitsPerPage: 3,
But there's something off. There's 334 pages and 3 results per page which would mean 1002 results, but the response says there is a total of 2860354. Experimenting with some other search terms such as 'a' 't' and 'long' gives the same results. 334 pages, but varying hits. Playing with different values for the hitsPerPage changes the numbers, but it looks like all combinations lead to a total resultset of 1000 results.
Not so yay 😔
So I googled for algolia max results to see if others have this. The top hit was actually the Algolia Pagination docs, which states:
1000 hit limit
By default, Algolia limits the maximum number of hits that can be retrieved via a query to 1000. This restriction is in place to not only guarantee optimal performance, but also to ensure your data cannot be easily extracted. For the vast majority of use cases, the default of 1000 hits is more than enough.
Bummer, right? Apparently we're not the first to do this and they actually took precautions to prevent people from doing what we are doing.
Incidentally, by running into these docs, it turns out Algolia has a very nice module, which also turned out to be easy to set up with the Untappd client id and key (left out in below snippet):
First let's install it:
$ yarn add algoiliasearch
And then put it to work ..
// scrape_algolia.js
const algoliasearch = require("algoliasearch");
const client = algoliasearch("XXX", "YYY");
const index = client.initIndex("beer");
index
.search("leffe", { hitsPerPage: 1000 })
.then(({ hits }) => {
console.log(hits.length);
})
.catch((err) => {
console.log(err);
});
Running this gives us, after a short wait, 1000 hits. This is great in itself as the code is a lot cleaner and we don't have to create the loop to get all our 1000 results, but doesn't solve our challenge of getting all the data. We're still limited to 1000 results.
I of course first looked if we could override this limit. There is a way to change this, by setting the client settings:
index.setSettings({
paginationLimitedTo: 1000,
});
But it turns out you can only do this with an API key that has admin rights. Makes sense. So looks like we're stuck with this limit of 1000 per search.
To the drawing board!
So one way to tackle this would be to search for 1000 results with a, then for results with b etc. and then combine those. In an ideal world we end up with 27 * 1000 = 27.000 results, assuming we can find a way to tell Algolia not to fuzzy search but match the first letter. But that leaves us with under 1% of the complete list. So what else can we do?
The real challenge we have is the fact there is a hat with around 2 million names in it. We can ask the hat for any value and the hat will gives us up to thousand names that match that value. But there is no way to tell if we ever got handed all the possible names, even if we somehow ask all right questions.
So I stepped away from the problem for a little bit. Coming back I went over a few ideas ..
Screaming Frog
If you don't know, Screaming Frog SEO Spider is a nifty tool that crawl your site and give SEO advice. I ran untappd.com through to see if it would find all pages. That way we at least have a collection with all possible names, and then we can query those in Algolia. Unfortunately, I couldn't get it to retrieve more than around 8.000 (HTML) results. Hardly the set we're looking for. In this case this isn't an option.
Googling beer names
Knowing our biggest challenge is finding out all the names I considered googling a list of Beer names which we can then use as a query set for the Untappd algolia search. I found a few, but realised spelling can be different, and the lists weren't near as complete as what it would need to be. Too bad.
Going at it from a User perspective
Untappd also has a feature where you can see the Unique beers a user checked in with. And there is some serious boozers out there, such as this one with 1.226 unique beers. When browsing those I noticed there is no cap in the results displayed (keep pressing Show More). Which makes sense, because you always want to be able to see all your unique checkins. This made me thinking of maybe crawling all the users and then somehow retrieve their unique beers and friends. But it would be cumbersome. Besides, there's even more users than beers, and we don't have a guarentee all users are connected and that they accumulatively have drank all the beers listed in the system. So this could work, but it would be too time and effort consuming for my taste.
Returning to the search on untappd
I then tried approaching the data differently. Maybe instead of finding all the beers we could find breweries instead. If we have a list of breweries, we can query the data for the beers. Surely there's no breweries with 1000+ beers. right? But alas, looking at the search results for "a" the same problem occurs as with the beers.
Brute force
But then I figured we could probably make use of a brute force method 🤔. This is an approach best left untouched but since we've running out of options here it's worth exploring. If we can search for beers for a specific brewery (by ID) then our results should be below 1000 per request. By doing some sampling I saw no breweries who brew more than 1000 beers. Of course there's no way of knowing the IDs of the breweries, which is why we would just throw sequentual numbers at the system and hope for results back. Hence the 'brute' part.
I checked in the Algolia search documentation if you can limit the search results by checking other attributes, and luckily you can:
const index = client.initIndex("beer");
index
.search("", { hitsPerPage: 1000, filters: `brewery_id = 5` }) // 5 is the brewery id of "Leffe"
.then((data) => {
console.log(data);
})
.catch((err) => {
console.log(err);
});
This could work!
I ran above example, for the brewery "Abbaye de Leffe" and got 165 beer results. This seems perfect, but looking at the Brewery page itself it says on the top they have 27 beers 🤔. That's quite a difference.
So to find out the difference I put the JSON data from the algolia search results in my editor and pulled up the beer list. I then went from the top to see if I could find any differences that would help me explain the difference in results.
At first the list goes equally for a while, but then there is a few results in the JSON that's not on the website:
- Leffe Brune / Bruin (2019)
- Leffe d'Été / Zomerbier (2019)
- Leffe Blonde / Blond (2019)
- Leffe Rituel 9° (2019)
- Leffe Royale Cascade IPA (2019)
- Leffe Ruby (2019)
- Leffe Blonde / Blond (2020)
- Leffe Royale Whitbread Golding (2019)
- Leffe Tripel 2020 etc.
Looking at the attributes of these beers there's no indication these should be different than the other beers, but the fact they all have years in their name, whilst the overview on the website has no mention of 2019 or 2020 leads me to believe these might be filtered out. Unfortunately, it turns out Algolia doesn't support suffix searching nor filtering, so we can't limit the dataset while searching. We can however, filter those results out after we get the initial response.
const index = client.initIndex("beer");
index
.search("", {
hitsPerPage: 1000,
filters: "brewery_id = 5",
})
.then((data) => {
const res = [];
data.hits.map((beer) => {
// Skip beers with years in them (201*)
if (beer.beer_name.indexOf("201") < 0) {
res.push(beer);
}
});
console.log(res.length); // Checking how many results we get
})
.catch((err) => {
console.log(err);
});
We went from 165 beers to 128. Not quite the 27 we expected, but looking at the remaining results that are not on the site they are all out of production, so we can alter the query and try again:
filters: "brewery_id = 5 AND in_production = 1";
This time when we run the script we end up with .. 27! Nice. Time to automate things.
Automating the search
So we now have a battleplan
- Loop through a set of numbers (1 to X)
- Search for
breweriesmatching the letter - If we get data back store that info for the number, and:
- Find
beersmatching the brewery ID - Saving the found beers into a results as well
As I said before, I usually would store all info in a variable in memory, but as we know we can expect in the millions of results, it's probably better to use a database at this point. I went with Sqlite as it's lightweight and doesn't require a lot of setting up.
Also, to determin the max range of our loop, I fiddled with the numbers in the following:
breweryIndex
.search(``, { hitsPerPage: 1, filters: `brewery_id > 463619` })
.then((data) => {
console.log(data);
});
I tried different values for brewery_id to determin what the highest number in the system was. 1.000.000 gave me nothing, 300.000 which gave results, 750.000 no results, 450.000, etc. until I ended up with the highest ID being 463619, which will be our max in the loop.
After some work I ended up with the following, which covers looping through numbers, checks if there is a brewery with that number, and then saves the the results to a database table. I kept the loop quite small as it's just meant to validate the idea:
const algoliasearch = require("algoliasearch");
const sqlite3 = require("sqlite3");
// Set up Algolia
const client = algoliasearch("xxx", "xxx");
const breweryIndex = client.initIndex("brewery");
// Set up the database
const db = new sqlite3.Database("./booze.db");
db.run(
"CREATE TABLE IF NOT EXISTS breweries(id INTEGER PRIMARY KEY, name text)"
);
const findBreweriesById = async (id) => {
return new Promise((resolve) => {
console.log(`Checking for brewery with ID ${id}`);
breweryIndex
.search(``, {
hitsPerPage: 1000,
filters: `brewery_id = ${id} AND brewery_homebrewery = 0`,
})
.then((data) => {
if (data.hits.length > 0) {
resolve(data.hits[0]);
}
resolve(null);
})
.catch((err) => {
console.log(err);
});
});
};
// Main search function
const search = async (_) => {
// Loop from ID 1 to X
for (let index = 1; index < 10; index++) {
// Try to find a brewery with this ID
const brewery = await findBreweriesById(index);
// If it's found ..
if (brewery) {
// Log it out
console.log(brewery.brewery_name);
// And save it to the table
db.run(`INSERT INTO breweries(id, name) VALUES(?, ?)`, [
brewery.brewery_id,
brewery.brewery_name,
]);
} else {
console.log(`Nothing found for ID ${index}..`);
}
}
console.log("Finished searching!");
db.close();
};
search();
So after running this I ended up 5 records in the breweries table. Awesome. By the way, Table Plus can open the resulting .db file on MacOS.
We will need to expand the data of the brewery with all the values we want, but first let's finish the core of the script which is fetching the beers for the found brewery.
// Adding the beer index
const beerIndex = client.initIndex("beer");
// Add a table for thr beers
db.run(
"CREATE TABLE IF NOT EXISTS beers(id INTEGER PRIMARY KEY, brewery_id INTEGER, name TEXT)"
);
// Adding a function to find beers by the ID of the brewey
const findBeersOfBrewery = async (breweryId) => {
return new Promise((resolve) => {
beerIndex
.search("", {
hitsPerPage: 1000,
filters: `brewery_id = ${breweryId} AND in_production = 1`,
})
.then((data) => {
// Filter out the results that have a year in them
// (I found this method more elegant than the one we used above)
const result = data.hits.filter((beer) => {
return (
beer.beer_name.indexOf("2019") < 0 &&
beer.beer_name.indexOf("2020") < 0 &&
beer.beer_name.indexOf("2018") < 0
);
});
resolve(result);
})
.catch((err) => {
console.log(err);
});
});
};
// Expanding the result loop
db.run(`INSERT INTO breweries(id, name) VALUES(?, ?)`, [
brewery.brewery_id,
brewery.brewery_name,
]);
// Find any beers for this brewery
const beers = await findBeersOfBrewery(brewery.brewery_id);
// If we have some (some breweries are on the site but have no beers)
if (beers) {
// Log it out
console.log(`Found ${beers.length} beers`);
// And add them to the database
beers.map((beer) => {
db.run(`INSERT INTO beers(brewery_id, name) VALUES(?, ?)`, [
beer.brewery_id,
beer.beer_name,
]);
});
}
After running the script with these modifications we end up with records in both the breweries and beers tables! 🍻 There is some tidying up to do though. At the moment we don't check if a brewery record already exists and we also miss most of the extra information we were initially interested in. For the first I found this helpful answer which will do for now. Expanding the data is a matter of mapping.
Complete script
After tweaking a bit and adjusting to the above my final script looks like this:
const algoliasearch = require("algoliasearch");
const sqlite3 = require("sqlite3");
// Set up Algolia
const client = algoliasearch("xxx", "xxx");
const breweryIndex = client.initIndex("brewery");
const beerIndex = client.initIndex("beer");
// Set up the database
const db = new sqlite3.Database("./booze.db");
db.run(
`CREATE TABLE IF NOT EXISTS breweries(
id INTEGER PRIMARY KEY,
brewery_id INTEGER,
name TEXT,
city TEXT,
country TEXT,
image TEXT,
lat TEXT,
lng TEXT,
UNIQUE(brewery_id)
)`
);
db.run(
`CREATE TABLE IF NOT EXISTS beers(
id INTEGER PRIMARY KEY,
beer_id INTEGER,
brewery_id INTEGER,
name TEXT,
abv TEXT,
label TEXT,
type TEXT,
UNIQUE(beer_id)
)`
);
const findBreweriesById = async (id) => {
return new Promise((resolve) => {
console.log(`Checking for brewery with ID ${id}`);
breweryIndex
.search(``, {
hitsPerPage: 1000,
filters: `brewery_id = ${id} AND brewery_homebrewery = 0`,
})
.then((data) => {
if (data.hits.length > 0) {
resolve(data.hits[0]);
}
resolve(null);
})
.catch((err) => {
console.log(err);
});
});
};
const findBeersOfBrewery = async (breweryId) => {
return new Promise((resolve) => {
beerIndex
.search("", {
hitsPerPage: 1000,
filters: `brewery_id = ${breweryId} AND in_production = 1`,
})
.then((data) => {
const result = data.hits.filter((beer) => {
return (
beer.beer_name.indexOf("2019") < 0 &&
beer.beer_name.indexOf("2020") < 0 &&
beer.beer_name.indexOf("2018") < 0
);
});
resolve(result);
})
.catch((err) => {
console.log(err);
});
});
};
// Main search function
const search = async (_) => {
// Loop from ID 1 to X
for (let index = 1; index < 10; index++) {
// Try to find a brewery with this ID
const brewery = await findBreweriesById(index);
// If it's found ..
if (brewery) {
// Log it out
console.log(brewery.brewery_name);
// And save it to the table
db.run(
`INSERT OR IGNORE INTO breweries(
brewery_id,
name,
city,
country,
image,
lat,
lng
)
VALUES(?, ?, ?, ?, ?, ?, ?)`,
[
brewery.brewery_id,
brewery.brewery_name,
brewery.brewery_city,
brewery.brewery_country,
brewery.brewery_image,
brewery._geoloc.lat,
brewery._geoloc.lng,
]
);
// Find any beers for this brewery
const beers = await findBeersOfBrewery(brewery.brewery_id);
// If we have some (some breweries are on the site but have no beers)
if (beers) {
// Log it out
console.log(`Found ${beers.length} beers, adding them ..`);
// And add them to the database
beers.map((beer) => {
db.run(
`INSERT OR IGNORE INTO beers(
beer_id,
brewery_id,
name,
abv,
label,
type
) VALUES(?, ?, ?, ?, ?, ?)`,
[
beer.bid,
beer.brewery_id,
beer.beer_name,
beer.beer_abv,
beer.beer_label,
beer.type_name,
]
);
});
}
} else {
console.log(`Nothing found for ID ${index}..`);
}
}
console.log("Finished searching!");
db.close();
};
search();
And the data is showing up perfectly ..
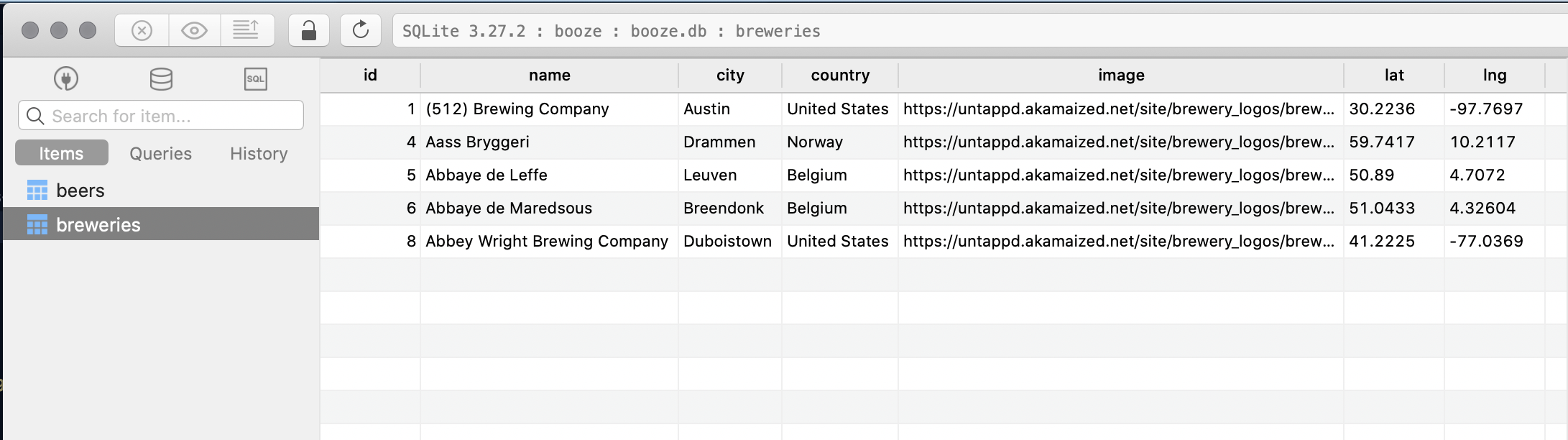 Breweries table
Breweries table
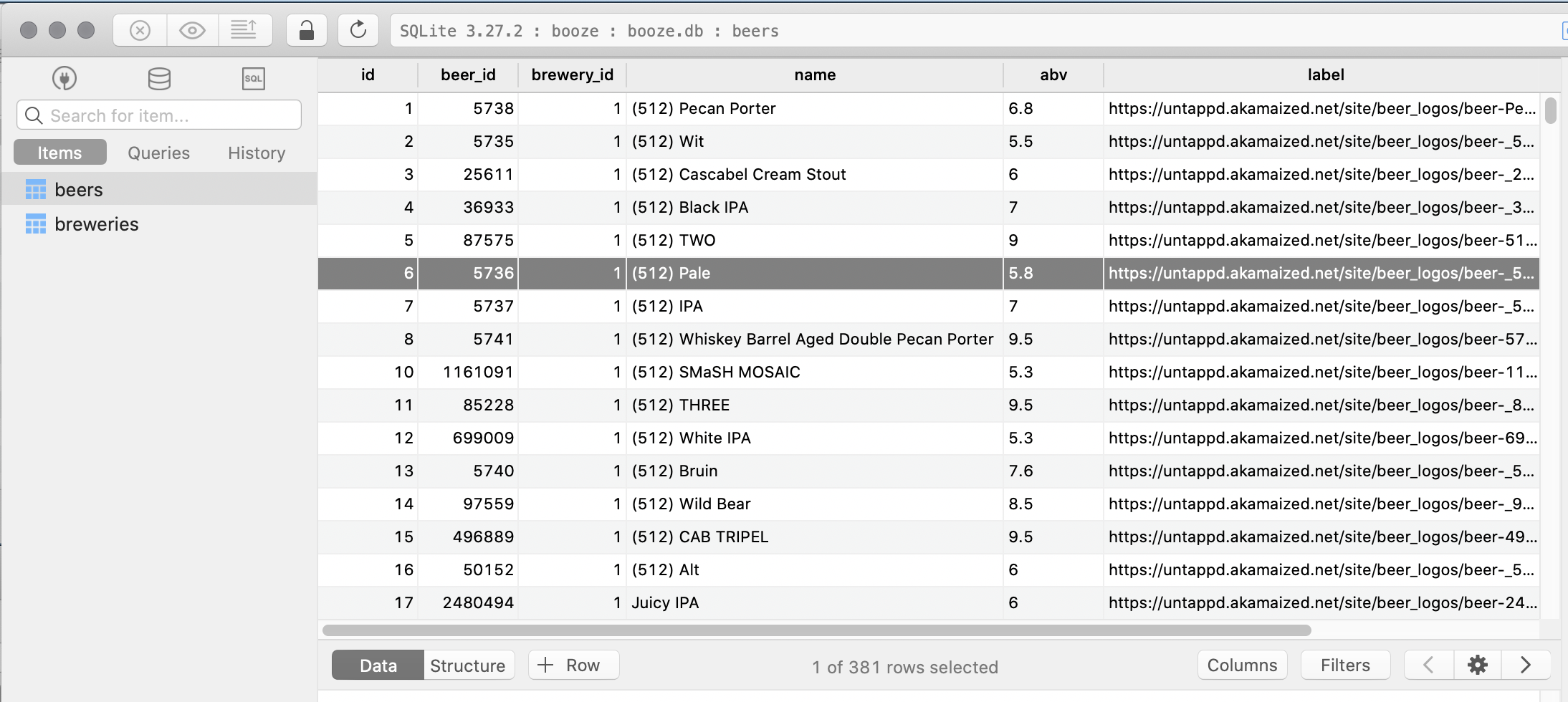 Beers table
Beers table
Conclusion
So there we have it! We have a semi brute-force automated script to retrieve all the data of breweries and beers that we want. Like I said in the beginning, this post isn't meant as a clear-cut way to retrieve this data, but rather a perspective on how to go about solving problems like this. It's very common the solution you go with isn't the one you initially thought of. And even more often than that, it turns out that solution doesn't scale or work because of unforeseen issues. Our job as creative developers is to keep coming up with alternative ideas and ways to solve a problem.
If you have any questions find me on twitter ✌🏻
Happy coding!